I wish pods were fully restartable
+Hi Erkan. Pod-X in my cluster is in CrashLoopBackOff. How can I solve this issue?
-Ohh:/ Most probably it is because of the known EKS issue. Just restart the pod.
+How?
-Just delete the pod.
+Really? May I delete any pod in my cluster?
-In theory, you can delete any pod of our application. Nevertheless, be careful :D
I don’t remember how many times I had this conversation, but I have never thought about whether pods are really restartable or not until recently. When I thought about it deeply, I noticed that pods are not fully restartable, they are re-creatable or partially restartable.
This blog post consists of my understanding and my comments. Please ping me if there is something wrong. https://twitter.com/erkan_erol_
Thinking out loud
What is “restart”? RE - START. It has “re” prefix. It means doing something again. So restart means starting again. Not “running again”. What is the difference?
We are using “rerun” for the things which finish in a short period such as cli commands. For example “Rerun kubectl delete secrets --all command to ensure that all secrets are deleted.” We mostly rerun a thing when some external things have changed and when we want to benefit from its execution for the changed state again.
We are using “restart” for the things which run until someone stops them such as daemon processes, computers, phones etc. For example, “Is the phone screen frozen? Just restart it.”
When do we restart a thing? Why do we like restarting so much? Or do we like it? We don’t like it so much, but we often need it. Right? Why? Why restarting things is the best solution of all times? What is the magic touch?
Let’s come to the point. Restarting works since it deletes temporary states inside processes. It works since we are not perfect in managing states and our codes may stick at some states because of unhandled states or some bugs.
Cloud Native World
After decades, there is a consensus in the software industry: Need for restart is inevitable so let’s make it less painful.
From the application point of view, these two attributes are pretty crucial
- Being stateless or having states as minimum as possible (see Processes )
- Maximize robustness with fast startup and graceful shutdown (see Disposability )
From orchestrator point of view, 2 features are must:
- Allow workloads to state their health statuses
- Restart failed/unhealthy workloads.
All problems seem solved. Right? Run multiple instances, restart unhealthy ones, achieve high availability. PERFECT!
Additionally, there are always some levels in software architectures and it is better to restart things in higher levels (implies smaller scope) -if possible- to reduce the overhead. Like restarting frozen Chrome instead of restarting PC.
A short summary of pods in Kubernetes
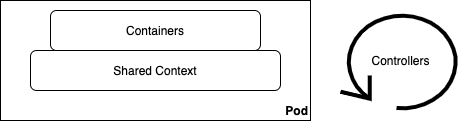
The main subject of this write-up is pods in Kubernetes. Let’s take a closer look at pods. Here are three quotes from the official doc:
-
“Pods are the smallest deployable units of computing that can be created and managed in Kubernetes.”
-
“A Pod is a group of one or more containers (such as Docker containers), with shared storage/network, and a specification for how to run the containers.”
-
“The shared context of a Pod is a set of Linux namespaces, cgroups, and potentially other facets of isolation…”
Shortly, Pod = Shared Context + Containers.

Since pods are the smallest and fundamental workloads in Kubernetes, to be able to restart pods is extremely crucial/necessary to reach the level at which we want to be by accepting to spend tremendous effort unrelated to our core application. ( See Kubernetes criticisms )
Restart Mechanisms for Pods
Quote the official doc,
A PodSpec has a restartPolicy field with possible values Always, OnFailure, and Never. The default value is Always. restartPolicy applies to all Containers in the Pod.
It seems Kubernetes is able to restart failed containers on behalf of us when they fail. Fine! What about unhealthy ones? We have livenessProbe
livenessProbe: Indicates whether the Container is running. If the liveness probe fails, the kubelet kills the Container, and the Container is subjected to its restart policy.
Shortly, the containers in pods are restartable. The temporary states inside containers are not a problem in Kubernetes world. Also, it doesn’t refresh the shared context so the overhead is so minimal. Everything seems perfect at container level until now.
What about the shared context under the containers? Do we have a mechanism to refresh it in pod level. Unfortunately, NO.
What? What happens when the shared context enters an invalid state somehow? Who is going to take care of it?
Controllers
Quote the official doc
- “In Kubernetes, controllers are control loops that watch the state of your cluster, then make or request changes where needed.”
My comments&expectations: Wow!!! It seems Kubernetes is designed in such a way that every agent has one job and does it well. There may be some problematic/missing pods in the cluster but we aim to solve this problem by using some controllers. Refreshing the whole pod may not be in the scope of pod controller, but it must be handled by other controllers in higher levels (See Fundamental theorem of software engineering).
Reality: There are a bunch of built-in controllers in Kubernetes. StatefulSets for stateful applications, DaemonSets for running an application in every node, ReplicaSets for running multiple instances with same pod spec, Deployments for declarative updates etc. However, none of them has functionality to fix a pod in CrashLoopBackOff state. For them, the state of a pod is “given.”. The only thing they do is to adapt their behavior according to this fact such as stopping rolling upgrades. BUT THEY DON’T TOUCH THE UNHEALTHY PODS.
Don’t you believe me? Here is an example: https://gist.github.com/erkanerol/528eab81c0db1cdcc3b9a13560d58047 After one minute, you are going to observe 3 pods in CrashLoopBackOff state which will stick at this state forever if you don’t delete them manually.
Comments and Wishes
The error in the example above may seem silly to you but there are a lot of real cases in which people hit similar issues because of different errors in different components: A problem in storage plugin, an anomaly in CNI plugin, an invalid state in shared volumes, etc.
At the end of the day, there is a state in the shared context of the pod and it is inevitable to do some mistakes that disrupt it. Why don’t we have a mechanism to clean it in pod level? Why do we assume that the state won’t be broken? Why do we compromise self-healing and expect manual intervention at such a core level?
Here are my ideas:
-
Pods can have a restart policy for the whole pod including the shared context. There can be maxRestartCount field like backoffLimit in Jobs to stop restarting repeatedly. I think it is better to restart only failed containers at first and then restart the whole pod if necessary.
-
Now, we mostly run pods via some high-level workloads (e.g. deployments) and what we do is to delete the pod and to allow the high-level controller to recreate them. However, “naked pods” are also in the game. Recreation can be a solution in higher levels, but it should not be the solution in pod level. Pods can be fully restartable and it can be possible to trigger a restart via the API and a kubectl command.
-
Built-in controllers can watch the state and intervene in the errors with some primitive, retry logic. For example, the deployment controller can delete a pod in CrashLoopBackOff state and recreate it from scratch. Sometimes, to schedule a problematic pod into another node solves a temporary problem in storage plugin and this feature can solve many cases like this.
Final Words
Kubernetes community is one of the best tech communities. I know the core team is very open for feedbacks and the community likes talking about possible improvements a lot. I just shared my personal opinions. I hope it will be beneficial to readers and increase awareness about this problem.